-
spark shuffle 피하고 broadcast join 으로 속도 빠르게 하기카테고리 없음 2020. 12. 5. 16:35
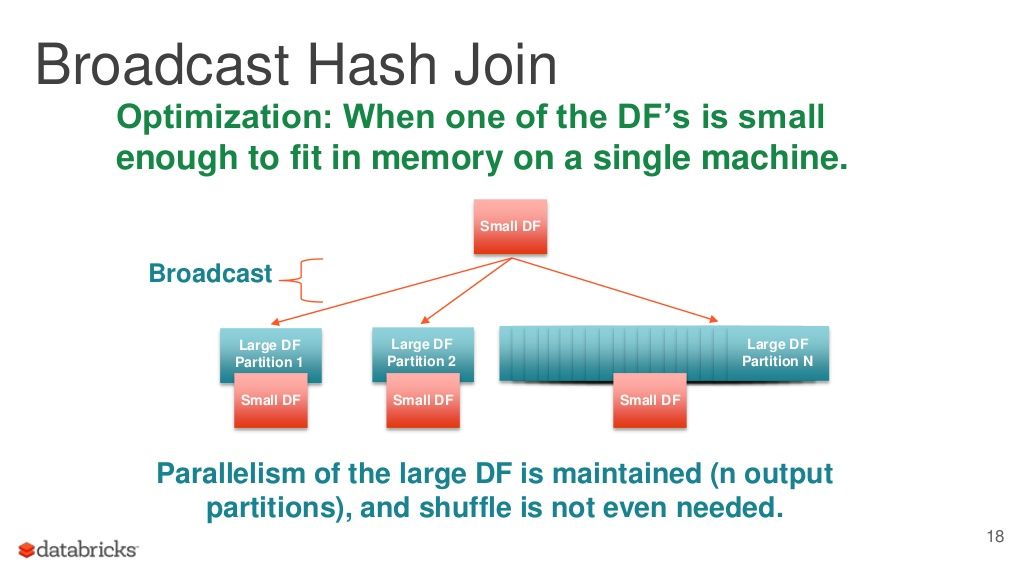
import org.apache.spark.sql.functions.broadcast BigDF.join(broadcast(SmallDF), SmallDF.col("ID") === BigDF.col("ID"))SELECT /*+ BROADCAST(SmallDF) */ * FROM LargeDF JOIN SmallDF ON LargeDF.key = SmallDF.key너무 큰 테이블(BigDF)과 작은 테이블(SmallDF)을 JOIN하였는데
나머지는 excutor는 모두 끝났는데 한 executor에서 계속 task 실행 중이라 작업이 오래 걸렸다.
spark의 shffle join은 두 테이블에서 각 executor에 알맞는 서로 data를 복사하기 때문에 속도가 느려진다.
한 테이블이 작다면 브로드 캐스트 조인을 사용하면 shuffle이 일어나지 않기 때문에 속도가 개선된다.